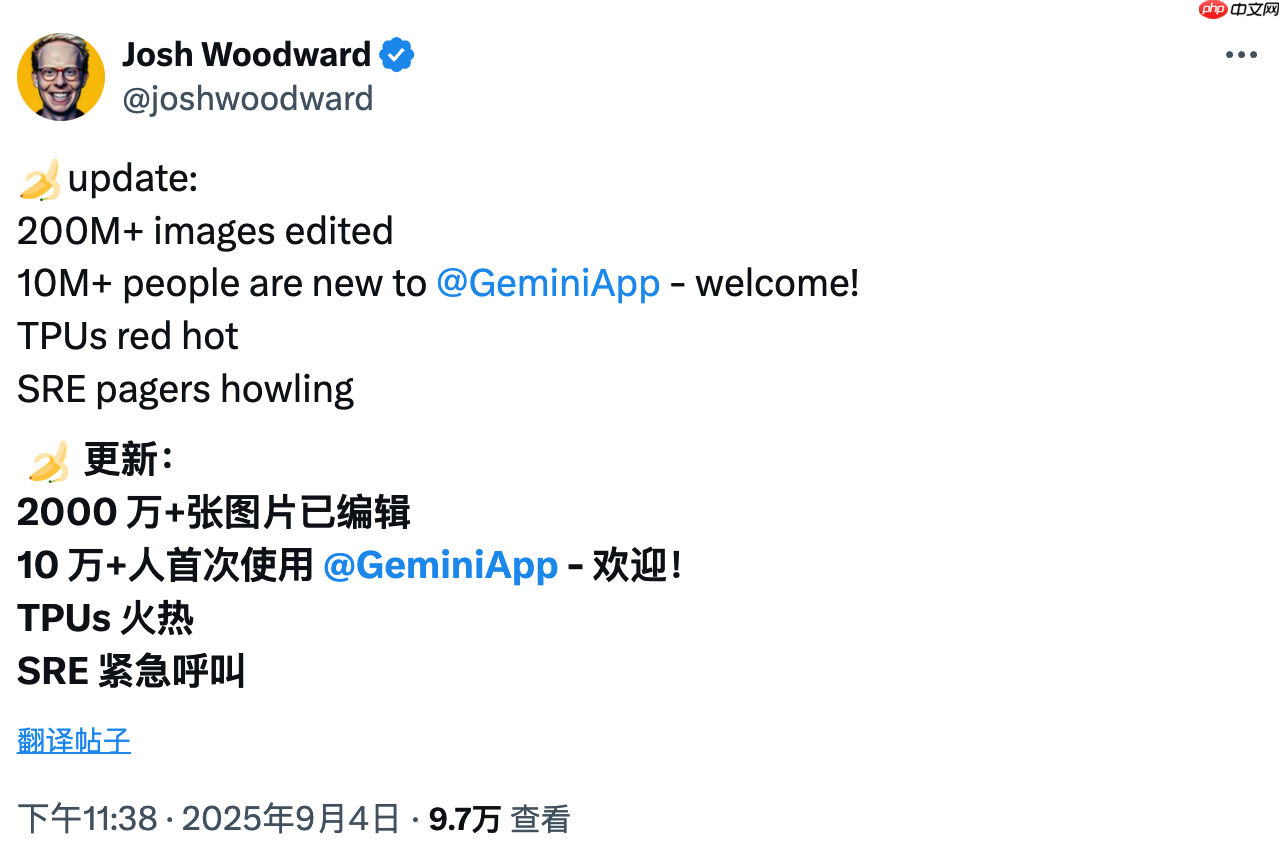
谷歌最新推出的 AI 实验项目“Nano Banana”上周迅速走红。谷歌实验室副总裁 Josh Woodward 在 X 平台透露,该功能上线后,已累计完成超过 2 亿次图像编辑操作,成功吸引超过 1000 万新用户首次使用 Gemini 应用。
谈及这一现象级热度,他幽默表示:“TPU 几乎被压垮,SRE 的警报声就没停过。”
Gemini 2.5 Flash Image(内部代号 Nano Banana)是谷歌当前最先进的图像生成与编辑模型,具备以下核心优势:...

阿里通义 Qwen 团队近日正式推出其最新闭源旗舰大模型——Qwen3-Max-Preview,该模型参数规模首次突破万亿量级,成为目前通义系列中体量最大、性能最强的模型。
在多项国际主流基准测试中,Qwen3-Max-Preview 表现出色,综合性能位居全球前列。其在通用知识理解(SuperGPQA)、数学推理能力(AIME25)、编程技能(LiveCodeBench v6)、人类偏好对齐(Arena-Hard v2)以及整体综合能力(LiveBench)等多个关键评测...

国际权威大模型评测平台chatbot arena的最新榜单显示,阿里巴巴的通义千问3(qwen3)以1433分的优异成绩,一举冲上全球总榜第三位,超越了grok4、claude4等众多强大的闭源模型,创下了开源模型的历史最高得分纪录。
更令人瞩目的是,它在数学、代码、复杂指令、长文本处理和工具调用这五项关键能力评测中,全部位列全球第一,成为中国AI领域首个“全能冠军”。而这一切,距离Qwen3正式开源仅过去了短短7天。
五项全能,刷新多项纪录
在五大核心能力的具体表现上,Q...

9月8日,魅族官方发布消息,宣布魅族22将于9月15日14:30正式亮相,届时将召开魅族22旗舰手机及flyme aios生态新品发布会。本次发布会除了主角魅族22外,还将带来ai拍摄眼镜、flyme auto 2智能车机系统以及pΛndΛer等多款全新产品。
魅族22
据官方透露,魅族22将搭载第四代骁龙8s移动平台,配备一块6.3英寸的直屏,采用0.8mm四等边白面板设计,物理四边框窄至1.2mm,延续了品牌一贯的极简美学风格。影像方面迎来重磅升级,配备5000万像素旗...

OpenBMB 正式发布并开源 MiniCPM4.1-8B,这是业界首个开源的混合推理大语言模型。该模型通过多项系统性创新,实现了在端侧设备上的极致高效运行,并支持深度推理与常规模式之间的一键自由切换。
该模型在 8B 参数量级下,从模型架构、训练数据、训练算法到推理系统四大层面进行深度优化,全面提升了端侧部署的可行性与性能表现。
核心优势
全球首个原生稀疏架构的深度推理模型,引入可训练的稀疏注意力机制 InfLLM v2,在代码生成、数学推导等复杂任务中,推理速度较同规...

在最新发布的论文中,英伟达推出的 jet-nemotron 系列混合架构语言模型在多项基准测试中表现优异,精度上超越或媲美 qwen3、qwen2.5、gemma3 和 llama3.2,同时实现了最高达 53.6 倍的生成吞吐量提升和 6.1 倍的预填充加速。与当前先进的 moe 全注意力模型如 deepseek-v3-small 和 moonlight 相比,jet-nemotron-2b 在 mmlu 和 mmlu-pro 等数学任务上的准确率也更胜一筹。
在 NVID...

阿联酋穆罕默德·本·扎耶德人工智能大学(mbzuai)在官网宣布,其与g42共同推出了一款低成本的推理模型“k2 think”。
新闻稿声称,K2 Think仅需320亿个参数,却能超越其他公司的、规模大20倍的推理模型。该模型基于阿里巴巴开源Qwen 2.5模型构建,并在Cerebras提供的硬件上运行和测试。
MBZUAI基础模型研究所所长Hector Liu告诉媒体,团队通过多种方法实现了高性能表现,包括:长链式思维监督微调(CoT) —— 一种逐步推理的方法;...

阿里通义 qwen 团队通过 hugging face transformers 库的 pr 提交了对 qwen3-next 系列的支持,信息显示将有一款名为 qwen3-next-80b-a3b-instruct 的模型。该系列定位为 “下一代基础模型”,主打极端上下文长度与参数效率。
据介绍,Qwen3-Next 系列模型在架构层面引入了三项核心创新。首先是 Hybrid Attention,它使用 Gated DeltaNet 和 Gated Attention...

由前 OpenAI 首席技术官 Mira Murati 创立的 Thinking Machines Lab 近日发布了其首篇技术博客:《在 LLM 推理中战胜不确定性》("Defeating Nondeterminism in LLM Inference")。
尽管将大语言模型的温度设置为 0,并使用完全相同的输入、模型和硬件,输出结果仍可能出现差异。这篇博客深入探讨了这一现象背后的原因,并提出了解决方案——如何实现 100% 可重复的大模型推理输出。
文章指出,造成这种...

字节跳动Seed研究团队近日发布了一项名为 AgentGym-RL 的全新框架,旨在利用强化学习技术训练大型语言模型(LLM)代理,使其能够在多轮交互中做出高效决策。
该框架采用模块化与解耦设计,具备出色的灵活性和可扩展性,能够适配多种主流强化学习算法。AgentGym-RL 涵盖了多个贴近现实的应用场景,为代理在复杂环境中的决策能力提升提供了有力支持。
为进一步提升训练效率,研究团队创新性地提出了 ScalingInter-RL 训练策略。该方法通过分阶段增加交互步数,使...